첫번째의 경우 cat 명령어가 직접 파일을 읽는 것이고, 두번째 명령어는 쉘이 파일을 읽고 cat에게 전달하는 것이다.
첫번째 명령의 경우 여러개의 파일을 읽을 수 있지만, 두번째는 한개의 파일만을 읽을 수 있다.
cat이 파일을 읽는 경우, 파일을 읽을때 마다 새로운 파일 디스크립터를 열기 때문에 파일 디스크립터 한계에 도달하면 "Too many open files" 오류가 발생할 수 있다. 하지만 쉘이 파일을 읽는 경우에는 이미 열려있는 표준 입력을 이용하기 때문에 추가적으로 파일 디스크립터를 사용하지 않는다고 한다.
따라서 대량이 파일을 읽을때는 두번째 명령어가 파일 디스크립터의 소비가 적을 수 있다.
※ 파일 디스크립터?열린 파일이나 입출력 자원들을 고유하게 식별하고 접근하기 위한 참조값
그리고 이러한 파일 디스크립터는 시스템 혹은 운영체제 별로 최대값이 설정되어있지만, 사용자에 따라 그 값을 바꿀 수 있다.
bandit0의 홈 디렉터리 아래에 있는 readme 파일 안에 bandit1의 비밀번호가 들어있다고 한다.
해당 비밀번호를 이용하여 bandit1에 ssh 접속을 하면 된다.
이 문제를 통해 파일을 읽는 방법에 대해 정리해보자
📌 풀이
파일을 읽을때는 cat 명령어를 이용해서 읽으면 된다.
이렇게 비밀번호를 확인했다면 서버에 bandit1 이라는 유저 아이디로 로그인을 해야하기 때문에, 현재 로그인 되어있는 bandit0에서 로그아웃 해줘야한다.
bandit0@bandit:~$ ls
readme
bandit0@bandit:~$ cat readme
Congratulations on your first steps into the bandit game!!
Please make sure you have read the rules at https://overthewire.org/rules/
If you are following a course, workshop, walkthrough or other educational activity,
please inform the instructor about the rules as well and encourage them to
contribute to the OverTheWire community so we can keep these games free!
The password you are looking for is: 비밀번호
bandit0@bandit:~$ logout
$ su - [유저네임]
위 명령어을 입력하면 로그아웃 하지 않아도 바로 사용자를 바꿀순 있지만, 워게임에서는 안될것이기 때문에 재접속을 하자.
터미널을 새로 열어서 bandit1으로 재접속 한다.
$ ssh bandit1@bandit.labs.overthewire.org -p 2220
| |__ __ _ _ __ __| (_) |_
| '_ \ / _` | '_ \ / _` | | __|
| |_) | (_| | | | | (_| | | |_
|_.__/ \__,_|_| |_|\__,_|_|\__|
This is an OverTheWire game server.
More information on http://www.overthewire.org/wargames
bandit1@bandit.labs.overthewire.org's password : 아까 봤던 비밀번호 입력
SSH란 secure shell의 약자로, 컴퓨터와 컴퓨터가 공용 네트워크를 통해 통신할때 보안적으로 안전하게 통신하기 위해 사용하는 네트워크 프로토콜을 말한다.
브라우저가 웹 페이지를 보여주기 위해 서버와 통신할때 HTTP 프로토콜을 이용하는 것과 같이, 서로 다른 컴퓨터들이 쉘을 이용하여 통신하기 위한 프로토콜이 필요했고 FTP,Telnet을 거쳐서 SSH가 사용되고 있다.
원격지의 컴퓨터에 쉘을 통해 안전하게 접속하기 위한 프로토콜
SSH의 등장배경은 ftp,telnet의 경우 컴퓨터가 통신을 할때 메세지가 암호화 되어있지 않아서(평문) 스니핑 공격에 노출되어있었다. 따라서 이러한 스니핑 공격을 막고자 SSH라는 네트워크 프로토콜이 탄생하게 되었다. SSH는 주로 데이터 전송이나 원격 접속시 사용된다.
※ sniffing? 사전적 의미로 냄새를 맡다, 코를 킁킁 거린다 는 뜻으로, 컴퓨터가 통신하는 과정에서 주고 받는 데이터를 몰래 열어보는 행위를 말한다.
이미지 출처- https://opentutorials.org/module/432/3742
🍪SSH Client & SSH Server
SSH Client
: 원격지의 컴퓨터에 접속하고자 하는 컴퓨터
리눅스와 Mac 과 같은 Unix계열의 운영체제는 기본적으로 ssh client가 설치되어있다. 하지만 윈도우 운영체제에는 설치되어있지 않다. 따라서 윈도우에서 Unix계열의 운영체제를 조작하고 싶다면 SSH Client를 설치해야한다.
‼️하지만 최근 윈도우를 사용하는 경우 기본 터미널에서도 ssh 접속이 가능하다. 맥과 동일하게 기본 터미널에서 ssh 명령어를 입력하여 접속하면 된다.
PuTTY로 ssh 접속을 하고자하는 경우, hostName에 접속하고자하는 원격지 컴퓨터의 IP주소나 도메인 이름을 적어준다.
SSH는 일반적으로 22번 포트를 사용하여 통신하기 때문에 22라고 자동 설정이 되어있다. 하지만 다른 번호를 사용하고 싶다면 Port 칸의 숫자를 바꿔주면 된다.
Connection type은 SSH를 선택해주면 된다.
기본 터미널에서 ssh 접속을 하게되면 포트번호는 자동으로 22로 설정된다. 만약 포트 번호를 22번이 아닌 다른 번호로 사용하고 싶은 경우 -p 옵션을 이용해 포트 번호를 지정해주면 된다.
아래 명령어를 입력하면 원격지 컴퓨터와 ssh 접속을 할 수 있다.
$ ssh [원격지에 접속하기 위한 사용자 아이디] @ [ 원격지 컴퓨터 IP or 도메인 이름] $ ssh [원격지에 접속하기 위한 사용자 아이디] @ [ 원격지 컴퓨터 IP or 도메인 이름] -p [포트번호]
위와 같은 과정으로 ssh 접속이 성공하면 ssh server의 컴퓨터를 원격으로 제어할 수 있게 되는 것이다.
SSH Server
:원격지의 컴퓨터
ssh를 통해서 어떤 컴퓨터를 제어하려고 하면, 제어의 대상이 되는 원격지에 있는 컴퓨터는 ssh server가 설치되어있어야한다.
ssh는 Unix 계열의 운영체제를 원격에서 제어하기 위한 것이다. 그렇기 때문에 원격지의 컴퓨터가 윈도우 운영체제를 사용하는 것은 일반적이지 않다. 윈도우는 보통 클라이언트 운영체제로 사용된다.
Unix 계열의 운영체제는 OpenSSH를 주로 사용한다. OpenSSH는 ssh client와 ssh sever를 모두 포함한다. 따라서 별도의 프로그램 설치없이 ssh 통신이 가능하다. 최근에는 윈도우도 OpenSSH를 지원하여 별도의 프로그램 없이 ssh 통신을 할 수 있다.
🍪SSH의 통신과정
: public key 🔒, private key 🗝️
SSH는 FTP,Talent과 같은 다른 네트워크 프로토콜에 비해 안전하다고 하는데, 어떻게 안전하게끔 통신을 할 수 있는 것일까?
방법은 주고 받는 데이터를 암호화시키는 것이다. 암호화를 한다면 중간에서 메세지를 가로채도 키가 없는 이상 무슨 메세지인지 알 수 없을 것이다.
SSH는 key를 사용하여 통신하려는 컴퓨터와 인증과정을 거치게 된다. 이때 key는 public key와 private key가 쌍으로 존재한다.
public key(확장자: .pub)
- 외부에 공개되어도 상관없는 키
- public key는 암호화만 가능하다. 복호화는 할 수 없다
private key(확장자: .pem)
- 외부에 노출되면 안되는 키
- public key와 쌍으로 같이 생성되어 본인의 컴퓨터에 저장되어있음
- public key를 통해 암호화된 메세지를 복호화 할 수 있음
마치 public key라는 자물쇠🔒로 데이터를 외부에서 보지 못하게 잠그고, 해당 자물쇠에 맞는 열쇠인 private key 🗝️로만 자물쇠를 풀 수 있는 것과 같다.
SSH Client는 public key와 private key를 생성한뒤 public key를 SSH Server에 복사하여 저장한다.
(SSH Server에서는 각각의 SSH Client의 public key를 구분하기 위해 따로 파일(~/.ssh/authrorized_keys)을 만들어서 관리해야한다.)
SSH Client에서 접속을 요청한다면, SSH Server는 해당 클라이언트의 public key로 암호화된 데이터를 전송한다.
그럼 클라이언트는 자신이 가지고 있는 private key로 받은 암호를 복호화하여 다시 SSH Server로 전송한다.
서버는 클라이언트에게 받은 메세지가 자신이 암호화한 내용과 동일하면 인증이 완료된다.
그래서 서로 관계를 맺고 있는 key의 쌍이라는 것이 확인되면 두 컴퓨터사이에 암호화된 채널이 형성되고, 키를 사용해 메세지를 암호화-복호화 하며 통신 할 수 있게 되는 것이다.
개념을 이용하면 객체를 그룹으로 만들어 분류할 수 있다. 개념은 공통점을 기반으로 객체들을 분류 할 수 있는 일종의 체와 같다.
객체에 어떤 개념을 적용해서 개념 그룹의 일원이 될때 객체를 그 개념의 인스턴스 라고 한다.
추상화는 두가지 차원에서 이루어진다.
1. 사물들간의 공통점은 취하고, 차이점은 무시하여 일반화를 통해 단순화 한다. (분류)
2. 중요한 부분을 강조하기 위해 불필요한 부분은 제거하여 단순하게 만든다. (일반화/특수화)
추상화는 분류와 일반화/특수화 기법을 적용한다.
객체지향 패러다임을 통해 분류와 일반화/특수화 기법을 적용하여 세상을 추상화한다.
객체란 특정한 개념을 적용할 수 있는 구체적 사물이다. 개념이 객체에 적용되었을때 객체를 개념의 인스턴스라고 한다.
개념
개념은 특정 객체가 어떤 그룹에 속할 것인지를 결정한다.
하트 왕비가 트럼프라는 개념에 속하는 이유는 트럼프를 생각할때 떠오르는 특징들을 가지고 있기 때문이다.
어떤 객체에 어떤 개념이 적용됐다는 것은, 그 개념이 가지고 있는 특징들을 만족시킬 수 있다는 것이다.
일반적으로 객체를 분류하는 틀로써의 개념을 이야기 할때는 3가지 관점이 함께 언급된다.
심볼, 내연, 외연
앨리스가 정원사,병사,신하,왕자와 공주,왕과 왕비들, 하트왕과 왕비의 몸이 납작하고 두 손과 두 발이 네모 귀퉁이에 달려 있기 때문에 트럼프라는 개념으로 묶었다.
심볼은 개념을 가리키는 이름으로, 앨리스의 이야기에서는 트럼프이다.
내연은 개념의 의미로, 몸이 납작하고 두 손과 두 발이 네모 귀퉁이에 달려 있다는 트럼프에 대한 설명이 바로 내연이다. 내연은 개념을 객체에게 적용할 수 있는지를 판단하는 기준이 된다. 하얀 토끼는 트럼프의 내연을 만족시키지 못하기 때문에 트럼프라는 개념을 적용할 수 없는 것이다.
외연은 개념에 속하는 객체들, 즉 개념의 인스턴스들이 모여 이뤄진 집합을 의미한다. 앨리스의 이야기에서 정원사,병사,신하,왕자와 공주,왕과 왕비들, 하트왕과 왕비가 트럼프의 외연이다.
심볼 : 트럼프 내연: 몸이 납작하고 두 손과 두 발이 네모 귀퉁이에 달려 있다 외연: 정원사,병사,신하,왕자와 공주,왕과 왕비들, 하트왕과 왕비
분류
분류란 특정한 객체를 특정한 객체집합에 포함 시키거나 포함 시키지 않는 작업을 의미한다.
분류란 객체에 특정한 개념을 적용하는 작업이다. 객체에 특정한 개념을 적용하기로 했을때 우리는 그 객체를 특정한 개념 집합의 멤버로 분류하고 있는 것이다.
개념을 통해 객체를 분류하는 과정은 추상화의 두가지 차원을 모두 이용하고 있다.
분류는 추상화를 위한 도구이다.
타입
타입은 개념과 완전히 동일하다
객체를 타입에 따라 분류하고 그 타입에 이름을 붙이는 것은, 결국 프로그램에서 사용할 새로운 데이터 타입을 선언하는 것과 같다.
객체를 만들때 가장 중요하게 생각해야하는 것은 이웃하는 객체와 협력하기 위해 어떤 행동을 할지 결정해야하는 것이다.
즉, 협력을 위해 어떤 책임을 지녀야 할지를 결정해야한다.
타입= 역할
객체의 타입을 결정하는 것은 객체의 행동뿐이다. (다형성)
어떤 객체가 어떤 타입에 속하는지를 결정하는 것은 객체가 수행하는 행동이다.
객체가 어떤 행동을 하느냐에 따라 객체의 타입이 결정된다. (객체가 하는 행동 = 내연)
객체 내부의 표현 방식이 다르더라도 어떤 객체들이 동일하게 행동한다면, 그 객체들은 동일한 타입에 속한다.
= 어떠한 행동을 해야하는 동일한 책임을 가지고 있다면 동일한 개념에 속한다.
동일한 데이터를 가지고 있더라도 다른 행동을 한다면, 서로 다른 타입으로 분류되어야한다.
같은 타입에 속한 객체는 행동만 동일하다면 서로 다른 데이터를 가질 수 있다.
동일한 행동 = 동일한 책임, 동일한 책임이란 동일한 메세지 수신을 의미한다.
동일한 타입에 속한 객체는 동일한 메세지를 받고 이를 처리 할 수 있지만, 내부 데이터 표현 방식은 다를 수 있기 때문에 처리하는 방식은 다를 수 있다. 이것은 "다형성"과 관련이 있다.
동일한 메세지를 서로 다른 방식으로 처리하기 위해서는 동일한 메세지를 수신 할 수 있어야하므로, 다형적인 객체들은 동일한 타입에 속하게 된다.
동일한 행동을 한다는 것은 동일한 책임을 가지고 있다는 것이고, 동일한 책임을 가진다는 것은 동일한 메세지를 수신 받는다는 것이다. 같은 타입에 속한 객체는 동일한 메세지를 수신 받지만, 내부 표현 방식에는 차이가 있기 때문에 메세지를 처리하는 방식에서 차이가 나타나게 된다. 이를 다형성이라고 한다.
캡슐화
객체의 내부 표현 방식과 무관하게 행동만으로 타입이 결정된다는 것은, 외부에 데이터를 알릴 필요가 없다는 것이다.
따라서 이러한 데이터는 외부로부터 감춰져야한다. 이는 캡슐화와 관련이 있다.
타입의 계층
일반화/특수화 관계
앨리스가 말하는 트럼프는 우리가 알고있는 트럼프 카드와 동일하지 않다.
앨리스가 말하는 트럼프는 더 정확하게 표현하면 "트럼프 인간"과 같다.
트럼프 인간 타입의 객체는 트럼프 타입의 객체가 할 수 있는 모든 행동을 할 수 있을뿐만 아니라 추가적으로 걸어다니는 행동을 할 수 있다.
트럼프 인간 타입은 트럼프 타입에 속한다.
트럼프는 트럼프 인간을 포괄하는 좀 더 일반적인 개념이다. 트럼프 인간은 트럼프보다 좀 더 특화된 행동을 하는 특수한 개념이다.
이 두 개념 사이의 관계를 "일반화/특수화 관계" 라고 한다.
객체지향에서 일반화/특수화 관계를 결정하는 것은 객체의 행동이다.
두 타입간에 일반화/특수화 관계가 성립하기 위해선 한 타입이 다른 타입보다 더 특수하게 행동하고, 반대로 한 타입은 더 일반적으로 행동해야한다.
그럼 더 일반적으로 행동하고, 반대로 더 특수하게 행동한다는게 무슨 말일까?
일반적인 타입은 특수한 타입 보다 더 적은 수의 행동을 가지고, 특수한 타입은 일반적인 타입보다 더 많은 수의 행동을 가진다. 단, 특수한 타입은 일반적인 타입이 할 수 있는 모든 행동 + 자신만의 행동을 수행한다.
일반화/특수화 관계에서 일반적인 타입은 특수한 타입보다 더 작은 가짓수의 행동을 가지지만, 더 큰 크기의 외연을 가진다.
슈퍼타입/서브타입
일반화 타입 = 슈퍼 타입 / 특수한 타입= 서브 타입
객체의 타입은 객체의 행동에 의해서만 결정된다.
객체를 타입으로 분류하는 것은 시간에 따른 상태변화를 배제하고, 정적인 관점에서 객체를 묘사 할 수 있도록 한다.
페이징은 프로세스를 페이지 라고 불리는 고정 크기로 나눈다. 물리 메모리 또한 페이지와 같은 크기인 프레임 으로 분할하여, 프로세스의 각 페이지를 물리 메모리의 프레임에 할당한다.
페이징 기법은 프로세스의 주소 공간을 페이지 크기로 자르기 때문에, 페이지의 경계를 고려하지 않고 코드 데이터 힙을 연이어 배치한다. 하지만 실제 운영체제에서는 코드,데이터,힙을 쉽게 관리하기 위해 데이터와 힙 영역이 서로 다른 페이지에서 시작되도록 배치한다.
페이지의 경계를 고려하지 않는다는게 무슨 말일까? 아래에서 예시를 통해 이해해보자.
페이지 크기는 4KB이고, 프로그램의 논리 주소 공간은 10KB라고 하자. 그리고 프로세스는 아래와 같이 구성된다고 해보자.
코드: 5KB 데이터: 3KB 힙: 2KB
이때 프로세스를 페이징 기법을 사용하여 메모리에 적재한다면 아래와 같다.
페이지 0: 처음 4KB(코드 일부 포함) 페이지 1: 다음 4KB(나머지 코드와 데이터 일부 포함) 페이지 2: 마지막 2KB(나머지 데이터와 힙의 일부 포함)
코드, 데이터, 힙이 논리 주소 공간에 순차적으로 배열되어 있더라도, 페이지 크기에 따라 분할되기 때문에 여러 페이지로 분할된다.
프로세스는 논리적으로 코드,데이터,힙 영역으로 정확히 분리 될 수 있지만 페이징 기법을 사용하면 4KB 라는 페이지 단위로 자르기 때문에 코드의 마지막 페이지 안에 데이터 영역이 포함되고, 데이터의 마지막 페이지 안에 힙 영역이 포함 될 수 있다는 것이다.
중요한 점은 이러한 프레임이 물리적 메모리의 어느 곳에나 분산될 수 있으므로, 논리적 순차 배열(코드 → 데이터 → 힙)이 논리 주소 공간에서만 유지되고 물리적 메모리에서는 유지되지 않는다는 것이다.
페이징은 고정된 크기로 프로세스를 분할하기때문에 홀의 크기가 결국 페이지 크기이다. 따라서 세그먼테이션과 달리, 홀의 크기에 대한 정보를 저장하고 있을 필요가 없다. 그래서 페이지 테이블은 페이지의 물리 주소를 저장하는 항목(프레임 번호) 1개만 가지고 있다.
페이지 테이블을 참조하여 프로세스의 페이지가 물리 메모리의 어떤 프레임에 매핑되어있는지 알 수 있다.
페이지 테이블은 프로세스 마다 만들어지는데, 하나의 프로세스를 페이지 단위로 나누었을때 만들어지는 최대 페이지 개수는 1MB, 약 100만개이다. 따라서 프로세스들의 페이지 테이블을 하나로 관리하기에는 용량이 너무 커지기 때문에 프로세스 당 하나씩 만들도록 설계한것이다.
(프로세스의 주소 공간 4GB / 페이지 크기 4KB) = 1MB
페이지 테이블
프로세스에서 스택과 힙 영역은 프로그램 실행 중에 동적으로 할당 받는 부분이기 때문에, 페이지 테이블의 많은 항목들이 비어있다.
또한 커널 코드도 논리 주소로 작성되어있기 때문에 페이지 테이블을 통한 매핑이 필요하다.
또한 페이지 테이블은 메모리에 저장하기 때문에 cpu 내부에 현재 프로세스의 페이지 테이블 시작 주소를 저장하는 레지스터가 필요하다. (Page Table Base Register)
단편화
프로세스 코드와 데이터가 주소 공간에 연속되어있기 때문에 내부 단편화는 마지막 페이지에서만 발생한다.
이렇게 가정하면 프로세스당 발생하는 단편화는 1/2 페이지 크기, 즉 2KB로 매우 작다.
페이징의 주소 체계
페이징의 논리 주소
페이징을 사용하는 시스템에서는 프로세스의 주소에 특별한 의미가 있다.
예를들어 프로세스의 크기가는 30이고, 페이지의 크기가 10이라고 하자. 그럼 프로세스는 3개의 페이지로 구성된다.
하나의 블록의 크기가 10이므로, 블록 안에서 주소를 0~9로 나누어서 생각할 수 있다.
프로세스의 주소에서 앞에 있는 숫자는 페이지의 번호를 나타내고, 뒤에 있는 숫자는 옵셋을 나타낸다.
옵셋이란 페이지 내에서의 상대적 주소를 말한다.
프로세스의 주소는 논리 주소이기 때문에, 실제 메모리의 주소를 알아내고 싶다면 페이지 테이블을 봐야한다.
페이지 테이블은 프로세스의 페이지가 어떤 프레임에 해당하는지 저장하고 있다. 따라서 논리 주소를 물리 주소로 변환하기 위해서는 페이지 번호를 프레임 번호로 바꾸기만 하면 된다. 이후 옵셋을 이용하여 해당 프레임의 위치로 가면 원하는 데이터가 있는 것이다.
이제 실제 메모리를 이용해서 생각해보자. 32비트 주소선을 가지고 있는 CPU와, 페이지의 크기가 4KB라고 한다면,
페이지 내의 각 바이트 주소(옵셋 주소)를 12비트로 나타낼 수 있다. 그럼 32비트 논리 주소에서 하위 12비트는 페이지 내에서 옵셋의 주소를 나타내고, 상위 20비트는 페이지 번호를 나타낸다.
프로세스의 논리주소를 보고 페이지 번호와 옵셋의 위치를 알아내서 위치를 특정할 수 있게 되는 것이다.
논리 주소 0x12345678의 페이지 번호와 몇번째 바이트에 위치한 주소인지 생각해보자.
하위 3자리 678은 페이지 내의 위치를 의미하고, 상위5자리인 12345는 페이지 번호를 의미한다.
즉, 이 주소는 0x12345번 페이지의 0x678번째 바이트에 대한 주소임을 알 수 있다.
논리 주소의 물리 주소 변환
페이지 테이블에는 프로세스의 모든 페이지에 대해 할당된 프레임 번호가 저장되기 때문에, 페이지 번호를 인덱스로 하여 페이지가 할당된 프레임 번호를 얻을 수 있다.
이렇게 얻은 프레임 번호를 페이지 번호와 바꾸고, 옵셋을 그대로 사용하면 논리 주소를 물리 주소로 바꿀 수 있다.
페이지 테이블의 문제점
페이징 기법이 단순하여 구현하기는 쉽지만, 페이지 테이블로 인한 성능 저하와 공간낭비 라는 두가지 문제점이 있다.
첫번째는 페이지 테이블은 MB 단위로 크기 때문에 cpu 내부에 둘 수 없어서 메모리에 저장하고 사용한다.
그래서 cpu가 메모리를 엑세스 할때마다 페이지 테이블 한번, 물리 메모리 한번 으로 총 2번의 물리 메모리를 엑세스 해야한다. 이는 프로세스의 실행속도를 심각하게 저하시킨다.
두번째는 페이지 테이블은 프로세스의 최대 크기에 맞춰 만들어지지만, 실제 프로세스의 크기는 그에 미치지 못하기 때문에 많은 공간낭비가 있다.
그럼 페이지 테이블로 인한 이 두가지 문제점을 해결하는 방법에 대해서 알아보자
2번의 물리 메모리 엑세스
메모리에서 값을 가져오기 위해서는 메모리를 한번만 접근하는 것 같지만, 사실은 두번 접근한다.
메모리는 cpu에 비하여 속도가 매우 느리기 때문에 메모리에 자주 접근 할 수록 프로세스의 실행시간이 길어지게 된다.
메모리 엑세스= 페이지 테이블 항목 읽기 1번 + 데이터 엑세스 1번
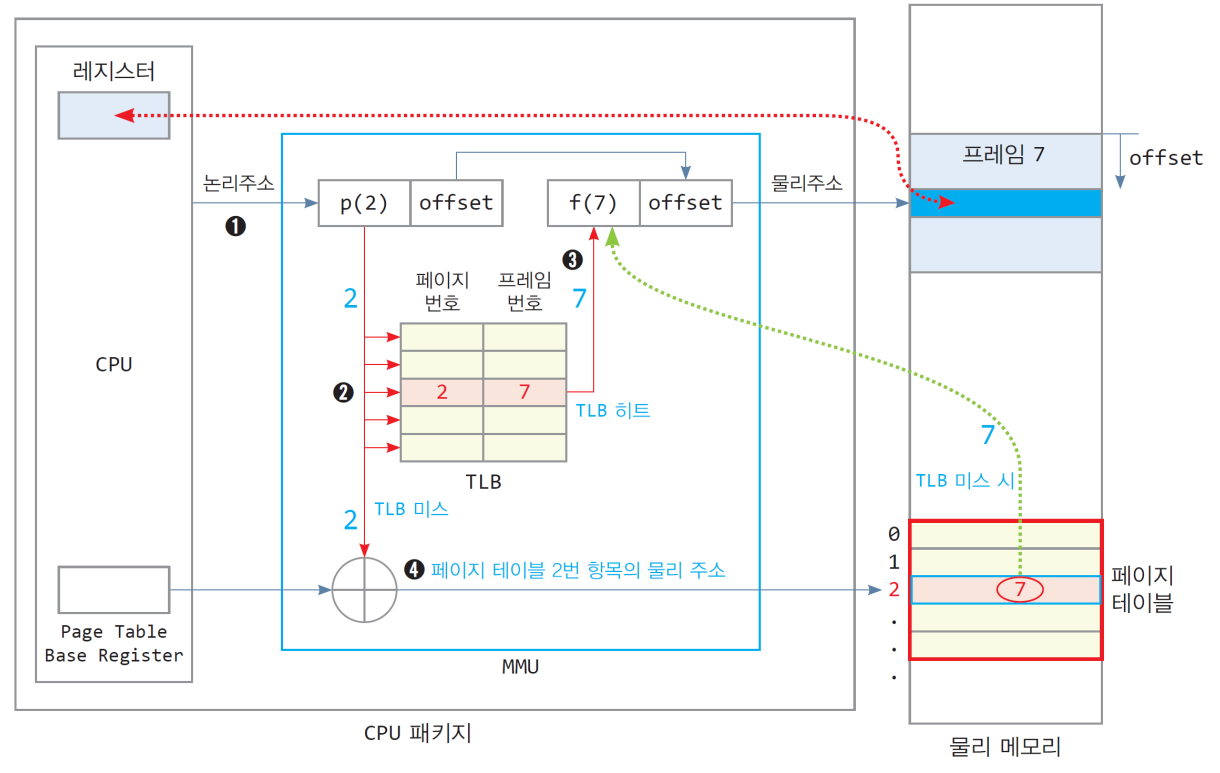
TLB를 이용한 2번의 물리 메모리 엑세스 문제 해결
TLB는 MMU 내에 두는 것으로 CPU가 최근에 접근한 페이지 번호와 페이지가 적재된 프레임 쌍을 저장하는 캐시 메모리이다.
따라서 TLB는 [ 페이지 번호(p), 프레임 번호(f)] 의 쌍을 항목으로 가지고 있다.
TLB는 논리 주소를 물리 주소로 변환할때 사용되므로 주소 변환용 캐시 라고도 불린다.
TLB 캐시에서 페이지 번호가 검색되는 방식은 일반 메모리와 많이 다르다. TLB는 페이지 번호를 순차적으로 검사하지 않고 모든 항목과 동시에 비교하여 단번에 프레임 번호를 찾아낸다.
주소 번지를 사용하지 않고 내용을 직접 비교하여 찾는 메모리 라고 해서 내용-주소화 기억장치 혹은 연관 메모리 라고도 부른다.
TLB의 크기는 cpu에 들어가야 하므로 작아야한다. 따라서 최근에 접근한 소수의 페이지와 프레임의 번호를 저장한다.
TLB를 이용한 메모리 엑세스
현재 대부분의 상용 cpu는 TLB를 내장하고 있다. TLB가 있으면, 반복적으로 메모리를 읽어오지 않아도 되기 때문에 프로그램의 실행속도가 매우 빨라지게 된다.
아래 그림을 통해서 자세히 이해해보자.
cpu로 부터 논리 주소가 발생하게 되면, 페이지 번호를 TLB로 전달한다.
페이지 번호와 TLB 내에 저장된 모든 페이지 번호가 동시에 비교 되고, TLB 히트가 발생하게 되면 바로 주소 변환이 일어나므로 페이지 테이블에 엑세스 하지 않아 물리 메모리를 1번만 엑세스 하게 된다.
만약 TLB 미스가 발생한다면 페이지 2번에 해당하는 프레임 번호를 알아내기 위해 메모리에 접근하여 페이지 테이블에서 프레임 번호를 찾은 뒤, TLB에 페이지 번호와 프레임 번호를 저장해둔다.
처음 TLB 미스가 발생하는 한 번의 경우에만 물리 메모리를 2번 엑세스 한다.
동일한 페이지를 연속하여 엑세스 하는 동안 TLB 히트가 계속 발생한다.
처음 TLB 미스가 발생한 이후, 미스한 페이지 번호와 프레임 번호가 TLB 캐시에 삽입되므로 그 후 부터는 거의 TLB미스가 발생하지 않는다. 이것이 바로 TLB를 활용하면 CPU의 메모리 엑세스 성능이 좋아지는 이유다.
TLB와 참조 지역성
TLB를 사용한다고 모든 프로그램의 실행 속도가 개선되는 것은 아니다. TLB는 순차 메모리 엑세스 패턴인 경우 매우 효과적이다.
하지만 프로그램이 메모리를 랜덤하게 엑세스 하는 경우, 참조 지역성이 잘 형성되지 않아 TLB 미스가 자주 발생하여 메모리에 엑세스 하는 횟수가 증가하게 된다.
TLB 성능과 도달범위
TLB의 성능은 TLB 히트율 이며 프로그램의 성능과 직결된다. TLB 히트율을 높이기 위해선 많은 항목들을 저장 하고 있으면 되지만, 비용이 매우 비싸진다는 문제점이 있다.
다른 방법으로는 페이지의 크기가 크면 TLB의 히트율이 높아진다. 하지만 페이지의 크기가 커지면 내부 단편화가 증가하여 메모리가 낭비 된다는 문제점이 있다. ( 내부 단편화의 크기 = 페이지의 크기 절반 )
TLB 도달범위란 TLB 캐시의 항목 수와 페이지 크기가 모두 고려된, TLB의 성능을 나타내는 지표로서 간단히 TLB항목 수 X 페이지 크기 로 계산된다.
TLB 히트율 = cpu의 메모리 엑세스 횟수에 대한 TLB 히트의 횟수의 비율이다.
TLB 도달 범위 = TLB 항목 수 X 페이지 크기
TLB를 고려한 컨텍스트 스위칭 재정립
페이지 테이블은 프로세스당 하나씩 존재하기 때문에, 동일한 프로세스 내에서 다른 스레드가 실행된다면 TLB에 들어있는 항목들을 교체할 필요가 없지만 다른 프로세스의 스레드를 실행하는 경우에는 페이지 번호에 따른 프레임 번호가 달라지기 때문에 TLB에 들어있는 항목들을 교체해줘야한다.
CPU의 모든 레지스터를 PCB에 저장
PCB에 있는 프로세스의 페이지 테이블의 주소를 MMU(CPU)의 Page Table Base Register(PTBR)로 로딩
운영체제가 새 프로세스를 실행시키거나, 실행중인 프로세스가 메모리가 필요할때 프로세스에게 물리 메모리를 할당 하는 것이다.
그렇다면 프로세스를 물리 메모리의 어느 위치에 적재할지는 어떻게 결정하는 것일까?
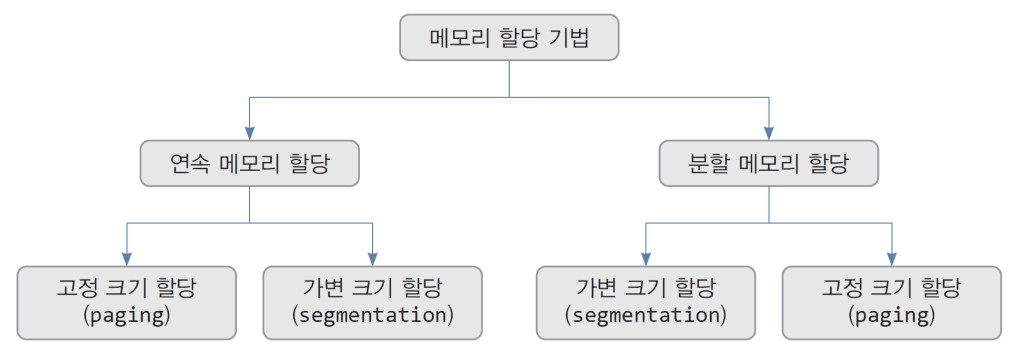
운영체제의 메모리 할당 기법은 아래와 같이 구분할 수 있다.
이미지 출처
연속 메모리 할당
연속 메모리 할당이란 프로세스가 할당 받은 메모리가 한 덩어리로 연속된 공간이라는 의미이다.
연속 메모리 할당은 고정된 공간에 프로세스를 할당하는지, 프로세스의 크기에 따라 가변적으로 변하는지에 따라 고정 크기 할당과 가변 크기 할당으로 나뉜다.
고정 크기 할당
메모리 전체를 파티션이라는 고정 크기로 분류하고, 파티션 1개에 프로세스 1개를 넣는 방식이다. 이 방식은 메모리를 고정 크기로 분리하기 때문에, 동시에 메모리에 적재하여 실행 할 수 있는 프로세스의 수가 정해져있다.
메모리를 n개의 파티션으로 나누었다면, 동시에 n개의 프로세스만 실행가능하다. n개의 프로세스가 실행되고 있을때 새로운 프로세스가 도착하면 실행중인 프로세스중에 하나가 종료될때 까지 대기해야한다. 또한, 프로세스의 크기가 파티션보다 작으면 메모리 공간이 낭비되고, 파티션 보다 크면 실행될 수 없다는 문제점이 있다.
가변 크기 할당
메모리를 프로세스 마다, 프로세스의 크기에 맞게 할당하는 방식이다. 처음부터 파티션을 나눠놓지 않고 각 프로세스에게 프로세스와 동일한 크기의 메모리를 할당한다.
연속 메모리 할당은 하나의 프로세스에게 연속된 메모리 공간을 할당해야하므로 메모리 할당의 유연성이 부족하다. 연속 메모리 할당 방식의 경우, 메모리에 비어있는 공간들을 합하면 충분히 할당 할 수 있음에도 불구하고 연속되어있지 않기 때문에 프로세스를 적재할 수 없는 경우가 발생한다.
연속 메모리 할당의 이러한 문제점을 해결하기 위해 분할 메모리 할당 기법이 제안되었다.
분할 메모리 할당
분할 메모리 할당이란 프로세스를 여러개의 덩어리로 분리하여 메모리에 할당하는 방법이다.
프로세스를 여러개의 덩어리로 분리할때 고정된 크기로 분리하면 고정 크기 할당, 크기가 다른 덩어리로 분리하면 가변 크기 할당이라고 한다.
가변 크기 할당 (세그먼테이션)
프로세스를 여러개의 덩어리로 분리하는데 이때 덩어리를 세그먼트라고 한다. 세그먼트들은 크기가 서로 다르기 때문에, 프로세스들이 실행되고 종료되기를 반복하고 나면 메모리에 적재된 세그먼트들 사이에 빈 공간이 생기게 되며 , 일부는 크기가 너무 작아서 새 프로세스에게 할당하지 못하는 메모리낭비(외부 단편화)가 발생한다.
세그먼테이션의 이러한 공간 낭비를 해결하기 위해 페이징 기법이 도입되었다.
고정 크기 할당(페이징)
세그먼테이션처럼 프로세스를 논리적인 덩어리로 분리하는 것이 아니라, 페이지라고 불리는 고정 크기로 분할한다.
물리 메모리 역시 페이지와 같은 크기로 분할하여 프레임이라고 부른다.
프로세스의 각 페이지를 메모리의 프레임에 하나씩 할당한다.
단편화
단편화란 프로세스에게 할당 할 수 없는 작은 조각의 메모리들이 생기는 현상을 말한다.
조각 메모리를 홀이라고 하며, 홀이 너무 작아 프로세스에게 할당 할 수 없을때 단편화가 발생한다.
단편화는 홀이 생기는 위치에 따라 내부 단편화와 외부 단편화로 나뉜다.
고정 크기 할당 시 파티션 내에 내부 단편화 발생
가변 크기 할당시 파티션과 파티션 사이에 외부 단편화 발생
연속 메모리 할당 구현
고정 크기 할당이든 가변 크기 할당이든 연속 메모리 할당을 위해선 하드웨어와 운영체제의 지원이 필요하다
하드웨어 지원
논리 주소를 물리주소로 변환하는 기능
다른 프로세스의 메모리 엑세스 금지 기능
base 레지스터 - 프로세스의 물리 메모리 시작 주소
limit 레지스터 - 프로세스의 크기
주소 레지스터 - 현재 엑세스하는 메모리의 논리주소
위 그림은 주소 변환과 메모리 보호가 일어나는 과정을 보여준다.
주소 변환 하드웨어는 다른 프로세스의 메모리를 보호하기 위해 주소 레지스터와 limit 레지스터의 값을 비교하여, 할당된 메모리 범위를 넘어섰다면 바로 시스템 오류를 발생시킨다 .
시스템 오류가 발생하면 cpu는 현재 프로세스를 강제 종료 시킴으로써 다른 프로세스나 운영체제가 적재된 영역을 침범하지 못하도록 메모리를 보호한다.
논리주소가 범위를 넘어서지 않는다면, 논리주소를 물리주소로 변환하는 과정이 실행된다.
논리 주소를 물리 주소로 바꾸기 위해 base 레지스터 값을 이용한다. base 레지스터의 값에 주소 레지스터 값을 더해 물리 주소를 구한다.
운영체제의 지원
프로세스별로 물리 주소 공간의 시작 주소와 프로세스의 크기가 다르기 때문에 새로운 프로세스가 실행될때마다,
프로세스의 물리 메모리 시작 주소와 크기 정보를 base레지스터와 limit 레지스터에 적재시켜야한다.
홀 선택 알고리즘/ 동적 메모리 할당
프로세스가 실행되고 종료되는 과정을 거치면서 메모리 공간에는 홀이 발생한다.
운영체제는 프로세스로 부터 메모리 요청이 들어왔을때 적절한 홀을 선택해서 할당해야하는데 이를 홀 선택 알고리즘 또는 동적 메모리 할당이라고 한다.
고정 크기 할당시
고정 크기 할당시 홀 선택 알고리즘은 간단하다. 메모리가 고정된 크기로 관리되기 때문에 홀들의 위치를 알 수 있도록 홀 리스트를 만들어서 관리하고 이 중에 하나를 선택하면 된다.
가변 크기 할당 시
하지만 가변 크기 할당시 운영체제는 메모리 전체에 걸쳐 비어있는 영역, 즉 홀마다 시작주소와 크기 정보를 구성하고 이들을 홀 리스트로 만들어서 관리해야한다. 그리고 메모리 할당 요청이 발생하면 리스트를 보면서 적절한 홀을 선택해야한다.
어떤 홀을 선택하느냐에 따라 성능이 달라지는데 대표적인 3가지 홀 선택 알고리즘이 있다.
first-fit (최초 적합)
홀 리스트를 검색하여 요청 크기보다 큰 홀 중 처음으로 만나는 홀을 선택한다.
best-fit (최적 적합)
홀 리스트를 검색하여 요청 크기를 수용하는 것중, 가장 작은 홀을 선택한다.
worst-fit (최악 적합)
홀 리스트를 검색하여 요청 크기를 수용하는 것 중, 가장 큰 홀을 선택한다.
이 중에서 fist-fit와 worst-fit은 메모리가 정렬되어있지 않다면, 리스트를 전부 검색해야하는 부담이 있다.
연속 메모리 할당의 장단점
논리 주소를 물리 주소로 바꾸는 과정이 단순하여 cpu가 메모리에 엑세스하는 속도가 상대적으로 빠르다.
또한 프로세스 마다 할당된 메모리 영역을 관리하기 위해 물리 메모리의 시작주소와 크기 정보만 관리하면 되므로 운영체제의 부담이 덜하다.
하지만, 메모리를 연속적으로 할당해야하기 때문에 홀 들을 합했을때 공간이 충분함에도 불구하고 메모리를 할당하지 못하는 상황이 발생 할 수 있다. 즉, 메모리 할당 유연성이 부족하다.
이런 경우 홀들을 한쪽으로 모아 큰 빈 공간을 만드는 메모리 압축 과정이 필요하다.
세그먼테이션 메모리 관리
프로세스를 구성하는 논리 블록을 세그먼트라고 한다.
세그먼테이션 메모리 관리 기법은 프로세스를 세그먼트로 나누고, 각 논리 세그먼트에 물리 메모리를 할당하는 방법이다.
세그먼테이션을 사용하는 운영체제들은 아래와 같이 세그먼트들을 나누어왔다.
코드 세그먼트
데이터 세그먼트
스택 세그먼트
힙 세그먼트
인텔은 세그먼테이션 기법으로 메모리를 관리하기 위해 프로세스를 코드 세그먼트,데이터 세그먼트,스택 세그먼트,엑스트라 세그먼트 로 나누고 cpu에 각 세그먼트의 물리 메모리 시작 주소를 저장하는 4개의 레지스터 cs,ds,ss,es를 둔다.
cpu에 각 세그먼트들의 시작 주소를 저장해야하기 때문에 cpu에 있는 레지스터에 따라서 세그먼트가 달라질 것을 생각해볼 수 있다. 컴파일러 역시 인텔cpu 구조에 맞춰 프로그램을 세그먼트로 나누고 컴파일 한다. 이러한 경우를 통해서 세그먼테이션 기법은 cpu에 매우 의존적임을 알 수 있다.
운영체제는 프로세스의 각 논리 세그먼트가 할당된 물리 메모리 위치를 관리하기 위해 세그먼트 테이블 을 이용한다.
세그먼트 테이블은 프로세스 내에 있는 세그먼트를 메모리의 어느 위치에 적재하였는지 알아내기 위해 필요하다.
시스템 전체에 1개의 세그먼트 테이블을 이용하여 현재 적재된 모든 프로세스들의 세그먼트들을 관리한다.
세그먼트 테이블의 항목은 세그먼트의 물리 메모리 시작 주소(base)와 세그먼트의 크기(limit) 로 구성된다.
논리 세그먼트 하나 당 테이블 하나의 항목이 생성된다.
세그먼트 테이블은 메모리에 저장된다, 따라서 cpu는 세그먼트 테이블의 시작주소를 저장하는 레지스터가 필요하다.
cpu에 의해 발생하는 논리 주소는 [세그먼트 번호, 옵셋] 형태이다.
세그먼테이션의 구현
하드웨어의 지원
논리 주소 구성
세그먼테이션의 논리 주소는 = [ 세그먼트 번호, 옵셋] 으로 구성된다.
여기서 세그먼트 번호란, 세그먼트 테이블에서 위치를 찾기 위해 부여된 번호이다. 따라서 세그먼트 번호를 보고 세그먼트 테이블에서 해당 항목을 찾으면 된다.
옵셋이란 세그먼트 내에서의 상대적 주소로, 물리 메모리에 있는 세그먼트 내에서 접근하고자 하는 위치를 상대적으로 표현한 값이다. 따라서 물리 주소로의 변환이 필요한 부분이다.
CPU
세그먼트 테이블은 메모리에 저장되므로, 세그먼트 테이블의 시작 주소를 저장할 레지스터가 필요하다.
프로세스의 세그먼트에서 메모리 접근이 필요하면, cpu는 세그먼트 테이블의 시작 주소를 이용하여 테이블 내에 저장된 정보를 이용해 물리 메모리에 접근한다.
cpu에 의해 발생하는 주소는 논리 주소이며, [세그먼트 번호, 옵셋] 의 형태이다.
MMU
MMU는 메모리 보호와 주소 변환 기능을 구현한다.
CPU에서 논리 주소가 발생되면 먼저 메모리에 저장된 세그먼트 테이블에서 세그먼트 번호에 해당하는 항목을 읽는다.
그리고 이 항목의 limit값과 옵셋 을 비교하여 범위를 넘어서는 경우 프로세스를 강제 종료시킨다.
그게 아니라면 항목에 들어있는 세그먼트의 물리 메모리 시작 주소와 옵셋의 값을 더하여 물리 주소를 출력한다.
세그먼트 테이블
세그먼트 테이블이 메모리에 있다면 논리 주소가 발생할때마다 메모리에서 정보를 읽어와야하기 때문에 실행 속도에 부담이 있다. 그렇기 때문에 주소 변환 속도를 빠르게 하기 위해 세그먼트 테이블의 일부를 MMU 내에 두기도 한다.
운영체제의 지원
세그먼테이션 기법을 사용하기 위해선 사용자 프로그램은 컴파일러에 의해 사전에 정의된 세그먼트들로 분할되고 링킹 되어야하며, 기계명령 역시 [ 세그먼트 번호, 옵셋] 의 형식으로 만들어져야한다.
운영체제의 일부분인 로더 역시 실행 파일에 만들어진 논리 세그먼트들을 인지하고, 이들을 물리 메모리의 빈 영역에 할당 받아 적재하며 세그먼트 테이블을 갱신해야한다.
자원을 소유한 스레드들 사이에서 다른 스레드가 소유한 자원을 요청하여 모든 스레드가 무한정 대기하는 현상이다.
공유 자원에 대한 동기화 문제중 하나이다.
교착상태는 단일 cpu 환경과 멀티 코어 환경 모두에서 발생 할 수 있는 문제다.
교착상태는 사용자 응용프로그램 내에서 주로 발생한다. 커널은 교착상태를 고려하여 매우 정교하게 잘 작성되어있지만 사용자가 작성한 프로그램은 그렇지 않기 때문이다. 하지만 교착상태를 막도록 운영하는 컴퓨터 시스템은 거의 없다.
교착상태를 막기 위해서는 많은 시간과 비용이 들기 때문이다.
교착 상태 유발 요인
자원 멀티스레드가 자원을 동시에 사용하려는 충돌에서 발생
자원과 스레드 스레드가 실행되는 동안 한 개의 자원만 필요한 경우 교착상태가 발생하지 않는다. 하지만 여러 자원을 동시에 소유한채 실행되어야하는 경우 교착 상태가 발생할 수 있다.
자원과 운영체제 자원은 반드시 운영체제에게 할당 받는다. 여러개의 자원이 필요하더라도 한번에 한개씩만 할당 받을 수 있다. 만일 스레드가 운영체제로부터 필요한 자원을 한번에 모두 할당 받는다면 교착상태가 발생하지 않을 수도 있다.
자원 비선점 할당된 자원은 운영체제가 강제로 뻿지 못한다. 만약 강제로 빼앗아 기다리는 스레드에게 줄 수 있다면 교착상태가 발생하지 않는다.
교착 상태 모델링
컴퓨터 시스템은 자원 할당 그래프를 이용하여 교착상태를 알아낼 수 있다.
자원 할당 그래프란 컴퓨터 시스템에 존재하는 자원과 스레드들의 상태를 방향성 그래프로 나타낸것이다.
꼭짓점 - 스레드는 원, 자원은 사각형
간선 - 할당간선과 요청간선
이미지 출처: https://unnokid.github.io/Avoidance/
스레드들이 교착상태에 빠지면 아래와 같이 환형고리가 나타난다.
이미지 출처: https://jongone.com/posts/dead-lock/
컴퓨터 시스템이 작동하는 동안 계속 자원 할당 그래프를 유지 갱신한다면, 자원 할당 그래프를 검사하여 교착 상태를 발견하거나 교착 상태에 빠진 자원과 스레드들을 알아낼 수 있다.
교착상태 해결방법
코프만 조건
코프만은 교착상태를 유발 할 수 있는 4가지 필요충분 조건을 제시하였다. 이 4가지 조건이 모두 충족되는 환경에서는 교착상태가 발생할 가능성이 있다는 것이다.
상호배제 - 자원은 한 번에 한 스레드에게만 할당
소유하면서 대기 - 스레드가 자원을 소유하면서 대기
강제 자원 반환 불가 - 할당된 자원은 강제로 빼앗지 못함
환형 대기 - 자원을 소유하면서 다른 자원을 요청하는 환형 고리
달리 말하면, 4가지 조건 중에서 한가지라도 만족하지 않는다면 교착 상태가 일어나지 않는다는 것이다.
교착 상태를 해결하는 방법에는 4가지가 있다.
교착 상태 예방
교착 상태 회피
교착 상태 감지 및 복구
교착 상태 무시
교착 상태 예방
교착 상태 예방은 애초에 교착 상태가 발생하지 못하도록, 코프만 조건 중 1개 이상을 만족 하지 못하도록 시스템을 설계하는 것이다.
상호배제 없애기 자원이 한 스레드에게 독점되는 것을 막는다는 것인데 이는 근본적으로 불가능하다.
소유하면서 대기 → 기다리지 않게, 모 아니면 도 전략 스레드가 자원을 소유하면서 다른 자원을 요청하여 대기하는 상황이 발생하지 않으려면, 처음부터 모든 자원을 소유하고 있으면 된다. 필요한 자원을 한번에 할당 받지 못하는 경우 모든 자원이 준비 될때까지 스레드의 실행을 중지시킨다. 또는 자원을 소유한 상태에서 새로운 자원이 필요하게 된다면, 현재 가지고 있는 자원을 반환하고 필요한 자원을 한꺼번에 모두 요청하는 방법이 있다.
자원 강제 반환 불가 → 자원의 선점을 허용 한 스레드에게 할당해준 자원을 운영체제가 강제로 빼앗을 수 있도록 한다. 이 경우, 빼앗긴 자원은 빼앗기기 전의 상태로 돌아갈 수 있도록 상태를 관리할 필요가 있다.
환형 대기 → 환형 대기 제거 모든 자원에 번호를 매기고, 반드시 번호순으로 자원을 할당받게 하는 방법이다.
교착 상태 회피
교착 상태 회피는 시스템적으로는 교착 상태가 발생할 가능성이 있지만, 자원을 할당하기 전 교착 상태에 빠지지 않을 것이라는 확신이 있을때 만 자원을 할당하도록 하는 방법이다. 대표적인 알고리즘으로 은행원 알고리즘이 있다.
이 알고리즘을 사용하기 위해서는 각 스레드가 실행 전 필요한 자원의 개수를 운영체제에게 모두 알려야하는데, 실행 전에 필요한것을 모두 아는 것은 사실상 불가능하므로 비현실적인 알고리즘이다. 또한 자원을 할당할때마다 교착 상태 가능성을 점검해야하므로 시스템의 성능을 많이 저하시킨다.
교착 상태 감지 및 복구
교착 상태에 대하여 예방이나 회피를 하지 않고, 운영체제가 교착상태를 감지하는 별도의 프로세스를 백그라운드에서 실행하여 교착 상태가 발견되면 그때 적절한 조치를 취하는 방법이다. 교착 상태를 감지하는 작업이 주기적으로 실행되어야하므로 이 또한 시스템에 많은 부담이 된다.
교착 상태를 해제하는 방법에는 아래와 같은 것들이 있다.
자원 강제 선점 교착 상태에 빠진 스레드중 하나를 선택하여 이 스레드가 소유한 자원을 강제로 빼앗아 다른 스레드에게 할당하는 방법이다.
롤백 교착 상태가 발생할 것으로 예상되는 스레드들에 대해 상태를 저장해두었다가, 교착 상태가 발생하면 이전 상태로 되돌리는 방법이다. 롤백 이후 스레드가 다시 작업을 하게 되면 여러 요인에 의해 자원 할당 순서가 달라지게 되어 교착 상태가 발생하지 않는다. 하지만 주기적으로 스레드들의 상태를 저장해야하므로 공간이 소모되어 시스템 성능 저하를 가져올 수 있다.
스레드 강제 종료 교착 상태에 빠진 스레드들중 하나를 강제로 종료시키는 방법이다. 하지만 어떤 스레드를 희생시킬지에 대한 문제가 남아있다.
교착 상태 무시
교착 상태 무시란 교착 상태가 발생하도록 내버려두는 방법이다. 문제가 발생하도록 내버려두었다가 문제가 발생하면 그때 대책을 세우면 된다는 것이다. 왜냐하면 범용 시스템에서는 교착 상태가 발생하더라도 파국을 부를 만한 작업을 실행시키지 않기 때문에 그때가서 처리해도 된다는 것이다. 이를 타조 알고리즘 이라고도 한다.
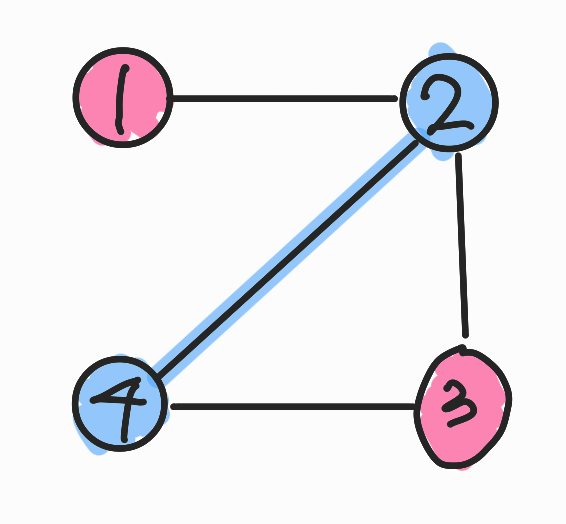
노드3으로 이동하여, 현재 바구니의 값과 반대인 바구니 B에 담는다. ( 바구니는 A,B 두개 밖에 없기 때문에 A 가 아니라면 B에 담아야한다)
방문하지 않은 노드2로 이동하여, 현재 바구니 값(B)와 반대인 바구니 A에 값을 담는다
노드 1에서 시작하여 노드들을 바구니에 번갈아 가며 담았을때, 위의 그림과 같이 구분된다.
결과적으로 같은 바구니A에 담긴 노드1,2는 인접하지 않는다.
이러한 과정을 노드2에서 시작, 노드3에서 시작하더라도 항상 같은 바구니에 있는 노드들은 인접하지 않는다.
노드 2에서 시작한 경우
노드3에서 시작한 경우
따라서 이 그래프는 이분 그래프 라고 할 수 있다.
잘 이해가 안간다면 이분 그래프가 안되는 경우를 보고 이해해보자
이분 그래프가 아닌 case
문제의 예시2번째는 이분 그래프가 아닌 경우이다.
왜냐하면 위의 그림에서 나와있듯이, 2 → 3 → 4 가 사이클을 형성하고 있다.
그런데 4 → 2 의 경우, B에 담긴 노드4가 B에 담긴 노드2와 인접하고 있다. 즉, 같은 바구니에 담긴 노드들이 인접했다.
따라서 이 경우는 이분 그래프가 될 수 없다.
그렇다면 어떤 상황에 같은 바구니에 담긴 노드들이 서로 인접할까?
정답은 다음 경로에 있는 노드가, 현재 노드의 바구니와 동일한 경우이다.
현재 노드가 바구니 A에 담겨있는데, 다음으로 탐색할 노드도 바구니A에 담겨있다면 이 경우 이분 그래프의 정의에 위배되는 것이다.
임의의 노드 한점에서 DFS를 수행한다. ( 중요한 것은 모든 노드에서 수행해야한다는것!)
아직 방문하지 않은 노드라면, 현재 바구니의 값과 다른 바구니의 값으로 설정한다.
이미 방문한 노드라면, 해당 노드의 바구니의 값을 확인하여 현재 바구니의 값과 일치한다면 No를 출력, 현재 바구니의 값과 일치하지 않는다면 Yes를 출력한다.
🐙 코드
package 고자프_수업정리.그래프;
import java.io.*;
import java.util.*;
public class P48_이분그래프 {
static ArrayList<Integer>[] list; // 그래프 저장
static StringBuilder sb; // 결과를 저장
static String[] visited; // 방문 상태 저장
static final String NOT_VISITED = "N"; // 초기값 설정
static boolean isBipartiteGraph; // 이분 그래프 여부 확인 플래그
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
StringTokenizer st;
int k = Integer.parseInt(br.readLine()); // 테스트 케이스 개수
sb = new StringBuilder();
for (int i = 0; i < k; i++) {
st = new StringTokenizer(br.readLine());
int V = Integer.parseInt(st.nextToken()); // 정점 개수
int E = Integer.parseInt(st.nextToken()); // 간선 개수
// 그래프 초기화
list = new ArrayList[V + 1];
visited = new String[V + 1];
for (int j = 1; j <= V; j++) {
list[j] = new ArrayList<>();
visited[j] = NOT_VISITED;
}
// 그래프 생성
for (int j = 0; j < E; j++) {
st = new StringTokenizer(br.readLine());
int u = Integer.parseInt(st.nextToken());
int v = Integer.parseInt(st.nextToken());
// 무방향 간선 추가
list[u].add(v);
list[v].add(u);
}
// 이분 그래프 판별
isBipartiteGraph = true; // 기본값
// 주어진 그래프가 연결그래프라는 보장 x -> 모든 노드에서 수행하기
for (int j = 1; j <= V; j++) {
if (visited[j].equals(NOT_VISITED)) {
checkBipartiteGraph(j, "A");
if(!isBipartiteGraph) break;
}
}
// 결과 저장
sb.append(isBipartiteGraph ? "YES" : "NO").append("\n");
}
// 결과 출력
bw.write(sb.toString());
bw.flush();
bw.close();
br.close();
}
static void checkBipartiteGraph(int x, String group) {
visited[x] = group; // 현재 노드를 방문 표시
String opposite = group.equals("A") ? "B" : "A"; // 반대 그룹 설정
for (int num : list[x]) {
if (visited[num].equals(NOT_VISITED)) { // 아직 방문하지 않은 노드
checkBipartiteGraph(num, opposite);
} else if (visited[num].equals(group)) { // 동일 그룹에 속할 경우
isBipartiteGraph = false; // 이분 그래프가 아님
return;
}
}
}
}
🧐 무방향 그래프로 저장하는 이유?
간선의 방향이 입력에서 명확히 주어지지 않으면 양방향 그래프로 처리하자.
🧐 모든 노드에서 탐색을 시작해야하는 이유?
문제의 조건에서 모든 노드들이 하나로 연결되어있다고 생각할 만한 부분은 없었기 때문에, 임의의 한 노드에서만 탐색을 하여서 이분 그래프인지를 따져선 안된다. 모든 노드에서 확인을 해줘야한다.
그래서 boolean isBipartiteGraph = true; 라는 변수를 이용하여 한번이라도 false 값으로 초기화 되면 , 그 그래프는 이분 그래프가 될 수 없도록 하는 것이다.
🐙 정리
이 문제는 간단히 정리하자면, 그래프를 이용한 DFS 응용문제이다.
왜 이 문제에서 왜 DFS를 사용하였고, 왜 두 그룹으로 나누는지에 대해서 생각해보면 좋을 것 같다.