메모리 할당
운영체제가 새 프로세스를 실행시키거나, 실행중인 프로세스가 메모리가 필요할때 프로세스에게 물리 메모리를 할당 하는 것이다.
그렇다면 프로세스를 물리 메모리의 어느 위치에 적재할지는 어떻게 결정하는 것일까?

운영체제의 메모리 할당 기법은 아래와 같이 구분할 수 있다.
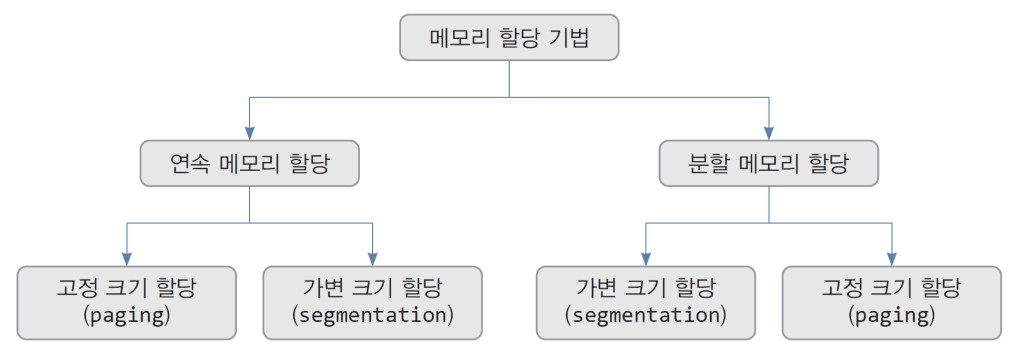
연속 메모리 할당
연속 메모리 할당이란 프로세스가 할당 받은 메모리가 한 덩어리로 연속된 공간이라는 의미이다.
연속 메모리 할당은 고정된 공간에 프로세스를 할당하는지, 프로세스의 크기에 따라 가변적으로 변하는지에 따라 고정 크기 할당과 가변 크기 할당으로 나뉜다.
- 고정 크기 할당
메모리 전체를 파티션이라는 고정 크기로 분류하고, 파티션 1개에 프로세스 1개를 넣는 방식이다.
이 방식은 메모리를 고정 크기로 분리하기 때문에, 동시에 메모리에 적재하여 실행 할 수 있는 프로세스의 수가 정해져있다.
메모리를 n개의 파티션으로 나누었다면, 동시에 n개의 프로세스만 실행가능하다. n개의 프로세스가 실행되고 있을때 새로운 프로세스가 도착하면 실행중인 프로세스중에 하나가 종료될때 까지 대기해야한다.
또한, 프로세스의 크기가 파티션보다 작으면 메모리 공간이 낭비되고, 파티션 보다 크면 실행될 수 없다는 문제점이 있다.
- 가변 크기 할당
메모리를 프로세스 마다, 프로세스의 크기에 맞게 할당하는 방식이다.
처음부터 파티션을 나눠놓지 않고 각 프로세스에게 프로세스와 동일한 크기의 메모리를 할당한다.
연속 메모리 할당은 하나의 프로세스에게 연속된 메모리 공간을 할당해야하므로 메모리 할당의 유연성이 부족하다. 연속 메모리 할당 방식의 경우, 메모리에 비어있는 공간들을 합하면 충분히 할당 할 수 있음에도 불구하고 연속되어있지 않기 때문에 프로세스를 적재할 수 없는 경우가 발생한다.
연속 메모리 할당의 이러한 문제점을 해결하기 위해 분할 메모리 할당 기법이 제안되었다.
분할 메모리 할당
분할 메모리 할당이란 프로세스를 여러개의 덩어리로 분리하여 메모리에 할당하는 방법이다.
프로세스를 여러개의 덩어리로 분리할때 고정된 크기로 분리하면 고정 크기 할당, 크기가 다른 덩어리로 분리하면 가변 크기 할당이라고 한다.
- 가변 크기 할당 (세그먼테이션)
프로세스를 여러개의 덩어리로 분리하는데 이때 덩어리를 세그먼트라고 한다. 세그먼트들은 크기가 서로 다르기 때문에, 프로세스들이 실행되고 종료되기를 반복하고 나면 메모리에 적재된 세그먼트들 사이에 빈 공간이 생기게 되며 , 일부는 크기가 너무 작아서 새 프로세스에게 할당하지 못하는 메모리낭비(외부 단편화)가 발생한다.
세그먼테이션의 이러한 공간 낭비를 해결하기 위해 페이징 기법이 도입되었다.
- 고정 크기 할당(페이징)
세그먼테이션처럼 프로세스를 논리적인 덩어리로 분리하는 것이 아니라, 페이지라고 불리는 고정 크기로 분할한다.
물리 메모리 역시 페이지와 같은 크기로 분할하여 프레임이라고 부른다.
프로세스의 각 페이지를 메모리의 프레임에 하나씩 할당한다.
단편화
단편화란 프로세스에게 할당 할 수 없는 작은 조각의 메모리들이 생기는 현상을 말한다.
조각 메모리를 홀이라고 하며, 홀이 너무 작아 프로세스에게 할당 할 수 없을때 단편화가 발생한다.
단편화는 홀이 생기는 위치에 따라 내부 단편화와 외부 단편화로 나뉜다.
- 고정 크기 할당 시 파티션 내에 내부 단편화 발생
- 가변 크기 할당시 파티션과 파티션 사이에 외부 단편화 발생
연속 메모리 할당 구현
고정 크기 할당이든 가변 크기 할당이든 연속 메모리 할당을 위해선 하드웨어와 운영체제의 지원이 필요하다
하드웨어 지원
- 논리 주소를 물리주소로 변환하는 기능
- 다른 프로세스의 메모리 엑세스 금지 기능

- base 레지스터 - 프로세스의 물리 메모리 시작 주소
- limit 레지스터 - 프로세스의 크기
- 주소 레지스터 - 현재 엑세스하는 메모리의 논리주소
위 그림은 주소 변환과 메모리 보호가 일어나는 과정을 보여준다.
주소 변환 하드웨어는 다른 프로세스의 메모리를 보호하기 위해 주소 레지스터와 limit 레지스터의 값을 비교하여, 할당된 메모리 범위를 넘어섰다면 바로 시스템 오류를 발생시킨다 .
시스템 오류가 발생하면 cpu는 현재 프로세스를 강제 종료 시킴으로써 다른 프로세스나 운영체제가 적재된 영역을 침범하지 못하도록 메모리를 보호한다.
논리주소가 범위를 넘어서지 않는다면, 논리주소를 물리주소로 변환하는 과정이 실행된다.
논리 주소를 물리 주소로 바꾸기 위해 base 레지스터 값을 이용한다. base 레지스터의 값에 주소 레지스터 값을 더해 물리 주소를 구한다.
운영체제의 지원
프로세스별로 물리 주소 공간의 시작 주소와 프로세스의 크기가 다르기 때문에 새로운 프로세스가 실행될때마다,
프로세스의 물리 메모리 시작 주소와 크기 정보를 base레지스터와 limit 레지스터에 적재시켜야한다.
홀 선택 알고리즘/ 동적 메모리 할당
프로세스가 실행되고 종료되는 과정을 거치면서 메모리 공간에는 홀이 발생한다.
운영체제는 프로세스로 부터 메모리 요청이 들어왔을때 적절한 홀을 선택해서 할당해야하는데 이를 홀 선택 알고리즘 또는 동적 메모리 할당이라고 한다.
- 고정 크기 할당시
고정 크기 할당시 홀 선택 알고리즘은 간단하다. 메모리가 고정된 크기로 관리되기 때문에 홀들의 위치를 알 수 있도록 홀 리스트를 만들어서 관리하고 이 중에 하나를 선택하면 된다.
- 가변 크기 할당 시
하지만 가변 크기 할당시 운영체제는 메모리 전체에 걸쳐 비어있는 영역, 즉 홀마다 시작주소와 크기 정보를 구성하고 이들을 홀 리스트로 만들어서 관리해야한다. 그리고 메모리 할당 요청이 발생하면 리스트를 보면서 적절한 홀을 선택해야한다.
어떤 홀을 선택하느냐에 따라 성능이 달라지는데 대표적인 3가지 홀 선택 알고리즘이 있다.
- first-fit (최초 적합)
홀 리스트를 검색하여 요청 크기보다 큰 홀 중 처음으로 만나는 홀을 선택한다.
- best-fit (최적 적합)
홀 리스트를 검색하여 요청 크기를 수용하는 것중, 가장 작은 홀을 선택한다.
- worst-fit (최악 적합)
홀 리스트를 검색하여 요청 크기를 수용하는 것 중, 가장 큰 홀을 선택한다.
이 중에서 fist-fit와 worst-fit은 메모리가 정렬되어있지 않다면, 리스트를 전부 검색해야하는 부담이 있다.
연속 메모리 할당의 장단점
논리 주소를 물리 주소로 바꾸는 과정이 단순하여 cpu가 메모리에 엑세스하는 속도가 상대적으로 빠르다.
또한 프로세스 마다 할당된 메모리 영역을 관리하기 위해 물리 메모리의 시작주소와 크기 정보만 관리하면 되므로 운영체제의 부담이 덜하다.
하지만, 메모리를 연속적으로 할당해야하기 때문에 홀 들을 합했을때 공간이 충분함에도 불구하고 메모리를 할당하지 못하는 상황이 발생 할 수 있다. 즉, 메모리 할당 유연성이 부족하다.
이런 경우 홀들을 한쪽으로 모아 큰 빈 공간을 만드는 메모리 압축 과정이 필요하다.
세그먼테이션 메모리 관리
프로세스를 구성하는 논리 블록을 세그먼트라고 한다.
세그먼테이션 메모리 관리 기법은 프로세스를 세그먼트로 나누고, 각 논리 세그먼트에 물리 메모리를 할당하는 방법이다.
세그먼테이션을 사용하는 운영체제들은 아래와 같이 세그먼트들을 나누어왔다.
- 코드 세그먼트
- 데이터 세그먼트
- 스택 세그먼트
- 힙 세그먼트
인텔은 세그먼테이션 기법으로 메모리를 관리하기 위해 프로세스를 코드 세그먼트,데이터 세그먼트,스택 세그먼트,엑스트라 세그먼트 로 나누고 cpu에 각 세그먼트의 물리 메모리 시작 주소를 저장하는 4개의 레지스터 cs,ds,ss,es를 둔다.
cpu에 각 세그먼트들의 시작 주소를 저장해야하기 때문에 cpu에 있는 레지스터에 따라서 세그먼트가 달라질 것을 생각해볼 수 있다. 컴파일러 역시 인텔cpu 구조에 맞춰 프로그램을 세그먼트로 나누고 컴파일 한다. 이러한 경우를 통해서 세그먼테이션 기법은 cpu에 매우 의존적임을 알 수 있다.
운영체제는 프로세스의 각 논리 세그먼트가 할당된 물리 메모리 위치를 관리하기 위해 세그먼트 테이블 을 이용한다.
세그먼트 테이블은 프로세스 내에 있는 세그먼트를 메모리의 어느 위치에 적재하였는지 알아내기 위해 필요하다.

- 시스템 전체에 1개의 세그먼트 테이블을 이용하여 현재 적재된 모든 프로세스들의 세그먼트들을 관리한다.
- 세그먼트 테이블의 항목은 세그먼트의 물리 메모리 시작 주소(base)와 세그먼트의 크기(limit) 로 구성된다.
- 논리 세그먼트 하나 당 테이블 하나의 항목이 생성된다.
- 세그먼트 테이블은 메모리에 저장된다, 따라서 cpu는 세그먼트 테이블의 시작주소를 저장하는 레지스터가 필요하다.
- cpu에 의해 발생하는 논리 주소는 [세그먼트 번호, 옵셋] 형태이다.
세그먼테이션의 구현
하드웨어의 지원

- 논리 주소 구성
세그먼테이션의 논리 주소는 = [ 세그먼트 번호, 옵셋] 으로 구성된다.
여기서 세그먼트 번호란, 세그먼트 테이블에서 위치를 찾기 위해 부여된 번호이다. 따라서 세그먼트 번호를 보고 세그먼트 테이블에서 해당 항목을 찾으면 된다.
옵셋이란 세그먼트 내에서의 상대적 주소로, 물리 메모리에 있는 세그먼트 내에서 접근하고자 하는 위치를 상대적으로 표현한 값이다. 따라서 물리 주소로의 변환이 필요한 부분이다.
- CPU
세그먼트 테이블은 메모리에 저장되므로, 세그먼트 테이블의 시작 주소를 저장할 레지스터가 필요하다.
프로세스의 세그먼트에서 메모리 접근이 필요하면, cpu는 세그먼트 테이블의 시작 주소를 이용하여 테이블 내에 저장된 정보를 이용해 물리 메모리에 접근한다.
cpu에 의해 발생하는 주소는 논리 주소이며, [세그먼트 번호, 옵셋] 의 형태이다.
- MMU
MMU는 메모리 보호와 주소 변환 기능을 구현한다.
CPU에서 논리 주소가 발생되면 먼저 메모리에 저장된 세그먼트 테이블에서 세그먼트 번호에 해당하는 항목을 읽는다.
그리고 이 항목의 limit값과 옵셋 을 비교하여 범위를 넘어서는 경우 프로세스를 강제 종료시킨다.
그게 아니라면 항목에 들어있는 세그먼트의 물리 메모리 시작 주소와 옵셋의 값을 더하여 물리 주소를 출력한다.
- 세그먼트 테이블
세그먼트 테이블이 메모리에 있다면 논리 주소가 발생할때마다 메모리에서 정보를 읽어와야하기 때문에 실행 속도에 부담이 있다. 그렇기 때문에 주소 변환 속도를 빠르게 하기 위해 세그먼트 테이블의 일부를 MMU 내에 두기도 한다.
운영체제의 지원
세그먼테이션 기법을 사용하기 위해선 사용자 프로그램은 컴파일러에 의해 사전에 정의된 세그먼트들로 분할되고 링킹 되어야하며, 기계명령 역시 [ 세그먼트 번호, 옵셋] 의 형식으로 만들어져야한다.
운영체제의 일부분인 로더 역시 실행 파일에 만들어진 논리 세그먼트들을 인지하고, 이들을 물리 메모리의 빈 영역에 할당 받아 적재하며 세그먼트 테이블을 갱신해야한다.
🐸 자료 참고
https://velog.io/@sda5124/%EB%A9%94%EB%AA%A8%EB%A6%AC-%ED%95%A0%EB%8B%B9
'cs > 운영체제' 카테고리의 다른 글
| 명품 운영체제 9장 - 페이징 메모리 관리 (1) | 2024.12.05 |
|---|---|
| 7장 교착 상태 (0) | 2024.12.03 |
| 명품 운영체제 8장 메모리 관리 - 메모리 주소 (0) | 2024.11.18 |
| 명품 운영체제 8장 메모리 관리 - 메모리 계층 구조와 메모리 관리 핵심 (2) | 2024.11.18 |
| 명품 운영체제 6장 스레드 동기화 (2) | 2024.10.23 |