✅ 문제
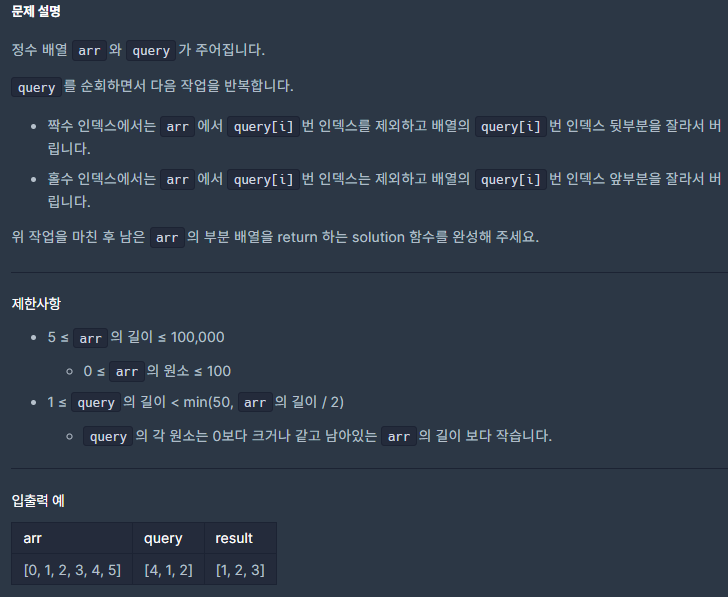
- 제한 사항

- 입출력 예시

문제가 이해하기 어렵지는 않은데 주의할건 배열을 자를때 query의 원소값은 인덱스 값이라는 것이다.
짝수 인덱스에서는 query[i] 의 값의 다음 인덱스 부터 없애야하고, 홀수 인덱스에서는 query[i] 값 이전을 없애야한다.
✅ 풀이
import java.util.*;
class Solution {
public int[] solution(int[] arr, int[] query) {
for(int i =0; i<query.length; i++) {
if(i % 2 == 0) {
arr = Arrays.copyOfRange(arr, 0, query[i]+1);
}else {
arr = Arrays.copyOfRange(arr, query[i], arr.length);
}
}
return arr;
}
}
처음 생각했던 방법은 query를 순회하면서 인덱스를 짝수와 홀수로 구분한다.
인덱스가 짝수인 경우에는 query[i] 값+1 이후의 값을 버리면 되기 때문에 copyOfRange 메서드를 사용하여 (처음~ query[i] +1) 범위까지 잘라서 배열에 담는다.
똑같은 방식으로 인덱스가 홀수인 경우에는 query[i]의 값 이전의 값을 버리기 위해 시작 지점은 query[i]로 설정한다.
사실 문제가 어렵지 않았기 때문에 풀이과정을 떠올리는것은 쉬웠다. 그런데 이 문제는 자세히 보면 배열의 값들을 굳이 삭제할 필요가 없다,
😲 이 문제는 사실 투 포인터
배열을 자르는 방식을 생각해보면 짝수인덱스 일때는 해당 인덱스의 원소값부터 뒷쪽을 자르고, 홀수 인덱스 일때는 해당 인덱스의 원소값 이전값들을 자른다.
그렇다면 원본 배열에서 어떤 인덱스 부터 ~ 어떤 인덱스 까지 출력할지 인덱스값을 정해줄 수도 있다.
즉, 계속해서 배열을 삭제를 할 필요 없이 시작과 끝 값만 알면 된다.
그렇다면 출력을 할 시작 인덱스와, 끝 인덱스를 설정하여 해당 문제를 풀어보자. ---> 투 포인터
import java.util.*;
class Solution {
public int[] solution(int[] arr, int[] query) {
int start = 0;
int end = arr.length - 1;
for (int i = 0; i < query.length; i++) {
if (i % 2 == 0) {
end = start + query[i];
} else {
start += query[i];
}
}
return Arrays.copyOfRange(arr, start, end + 1);
}
}
start 인덱스는 배열의 첫번째 원소부터, end 인덱스는 배열의 마지막 인덱스 부터 시작한다.
- query 인덱스가 짝수인 경우, end 인덱스를 조정
- query 인덱스가 홀수인 경우, start 인덱스를 조정
여기서 생각해볼 것은 start 인덱스의 위치가 배열의 시작 위치가 된다는 점이다.
이 예시를 가지고 생각해봤을때, start 인덱스의 처음 시작값은 0이다.
따라서 query[1] = 4가 가리키는 값은 arr[4] =4 이다.
그런데 query[1]=1 로 인해 start =1 이 된다. 이제 배열의 시작점은 바로 원본 배열의 arr[1] 에서 시작해야한다.
만약 시작 위치를 조정해주지 않는다면 arr[2]= 2 의 값이 되므로 [1,2,3,4] 에서 [1,2] 라는 값이 나오게 된다.
시작 위치를 arr[1] 의 위치로 바꾸면, 2번 인덱스가 가리키는 값은 3이 되므로 [1,2,3] 으로 올바른 값이 나올 수 있게 된다.
start 인덱스의 범위가 달라질때 마다 해당 지점이 새로운 배열의 시작점이 되어야하기 때문에 query[i]의 값을 누적해서 더해야한다.
end 인덱스의 값은 결국 달라진 시작점에서 부터 세어줘야하기 때문에 end = start+query[i] 로 설정해준다.
✅ 정리
문제의 조건만 보고 단순하게 기준을 세워서 배열을 잘라내야겠다라고 풀이 과정을 생각했었는데, 투 포인터를 사용했다면 굳이 배열을 자를 필요가 없었다.
겉으로 봤을때는 투포인터를 생각하지 못했지만 이렇게도 투포인터가 쓰인다는것을 알게되었다
'알고리즘 > 프로그래머스' 카테고리의 다른 글
| [프로그래머스] Day12 리스트 자르기 (0) | 2024.10.01 |
|---|---|
| [프로그래머스] Day12 2의 영역 자바 (2) | 2024.09.25 |